
Abstract
我们观察在RGB-T数据中观察到:模式相关经常出现在跨模态间和连续帧之间,因此,本文提出了一个cross-modal pattern-propagation (CMPP) 跟踪框架在空间域和时间域中扩散实例模式(原文是diffuse instance patterns)。
为了连接RGB-T模态,在模态内配对模式的跨模态相关性来揭露不同模态间的潜在联系 (原文是the cross-modal correlations on intra-modal paired pattern-affinities are derived to reveal those latent cues between heterogenous modalities.)。通过这些关系,有用的模态可以在不同RGB-T之间相互传播以填补模态内的模式传播。
进一步,考虑到连续帧之间的时序连续性,引入模态传播的思想到动态的时域中,这里长时历史上下文信息自适应相关并传递到当前帧中,实现更有效的信息继承。
实验证明提出的CMPP在2个RGB-T跟踪数据集上有着明显的性能提升。
核心:
- perform inter-modal pattern-propagation process for cross-modal spatial fusion;
- expound long-term context propagation module for temporal sequence encoding.
1. Introduction
引入RGB-T跟踪:视觉目标跟踪是CV中基础且具有挑战性的任务,并随着深度学习的发展在近几年中取得了巨大的成功。然而, 在低照度,严重遮挡和黑夜时还存在许多困难。由于目标信息的本质损失,当前的基于RGB的跟踪器经常在这些困难场景中不堪重负。相反地,热红外图像可以极大减少灯光的影响并有效补偿RGB图像来识别物体。由于红外图像的易于使用,基于双模态的RGB-T跟踪引起了极大的关注。
现存技术及其缺陷:现存的RGB-T跟踪方法经常在多模态特征上沿用传统的加权混合方法,或者直接扩展经典的RGB跟踪技术。比如,模态的权重引入到稀疏表达中;在将候选区域划分为patches后,patch权重被自适应学习以构建目标表达;所有模态的重要通道根据其置信度被选择;将part-based RGB跟踪修改为双模态跟踪,这里将来自两个模态的patches根据其重要性来排序。然而,所有这些方法都没有刻意去利用跨模式甚至是序列帧的内部模式关联,而这些模式关联在其中是高频出现的。
affinity值定义和分析:本文对2个大型RGB-T跟踪数据集(RGBT234,GTOT)的模式关联进行了统计分析,如下图。成对像素的亲和力(affinity)由欧式指标定义,affinity值越带,这对像素越相近。根据affinity值,定义每个RGB或者热红外图像内的相似对和不相似对。此外,在同一空间位置上有相同affinity值的条件下,确定了模式内部像素对的对应关系。换句话说,对应关系定义了一个匹配的关系模式,作为a second-order correlation。所以匹配的模态内的像素对(pair counterparts)被加,以此生成RGB和热红外模态间的统计比例。

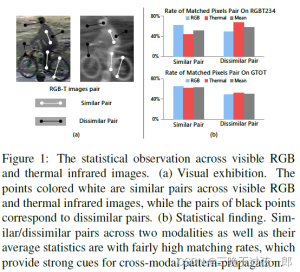
从上图,可以发现模态内的pattern counterparts高度出现在相似对和不相似对中,这称之为inter-modal pattern-correlation / a second-order relationship / relation on relation。此外,因为序列的连续性,图像patches往往在相邻帧之间出现很多次有冗余。因此我们定义帧间的pattern affinities,这是one-order intra-modal pattern-correlation。
本文做法:受到以上观察的启发,本文提出了一个CMPP跟踪框架来混合跨模态和模态内部的实例模式。凭借cross-modal second-order statistical correlations,我们提出了一个模态内部的模态传播方法来传递不同模态的模式。为了减少跨模态间的差异,跨模态的图像内亲和关系被推导以揭示不同模态之间的关联模式。通过这些关系,有用的模式可能在模态间互相传播,使得不同模态的特征被补偿。就连续帧间的时域连续性,我们将跨模态空间域的模式传播引入时域中来构建动态模式传播。在一个序列中,长时历史上下文被自适应关联并传递到当前帧中以更有效的信息遗传。
2. Related Work
Visual Object Tracking.最近基于相关滤波和CNN的跟踪器实现了最好的性能。
基于相关滤波的方法:
- MOSSE:先使用自适应滤波来目标跟踪,然后大量的基于相关滤波的方法涌现;
- Henriques等人:使用kernel技巧;
- Danelljan等人:将颜色属性作为目标特征;
- SAMF和KCF:使用尺度估计来处理不同的目标尺度问题。
基于CNN的方法将跟踪任务看作检测过程:
- MDNet:使用一个multi-domian learning训练了一个离线二进制分类模型从背景中识别目标。
- RT-MDNet:引入RoIAlign方法来提取目标更精准的表达;
- Park等人:在MDNet中引入元学习,通过跟踪过程中的时域信息来调整初始模型。
这些跟踪器表现很好但在一些环境下不堪重负,如低照度,有雾和黑夜。受限于RGB图像的本质缺陷。
RGB-T目标跟踪. RGBT近年来得到了越来越多的关注。基于稀疏表达的跟踪器由于其抑制噪声的能力表现很好。
- Wu等人级联多模态数据的候选区域并在模板空间内稀疏表达目标;
- Li等人提出一个协同稀疏表达模型来联合优化稀疏系数和模态权重;
- Li在跨模态排序模型中考虑了不同的模态的属性并学习基于patch的权重并构建目标表达;使用神经网络来自适应混合多个数据实现了完美的性能;
- Li提出选择重要的特征通道来跟踪;
- Zhu等人提出了一个特征聚合网络来加权多模态和多尺度特征用于鲁棒的目标表达。
这些方法使用多模态数据来构建目标表达,但他们忽略了跨模态数据的内部模式关联,其频繁出现并能用于互补。
3. Method

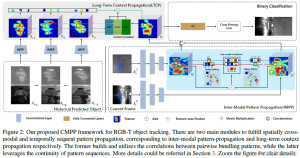
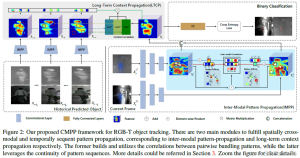
分为2个关键部分:
- perform inter-modal pattern-propagation process for cross-modal spatial fusion;
- expound long-term context propagation module for temporal sequence encoding.
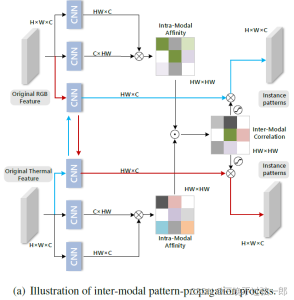
(a) 空间域的混合:模态间模式关联是在模态内关联的基础上定义的,它计算出单一模态中成对的捆绑模式的affinity。基于这种相关性,一个模态的模式可以被传播到另一个模态中。

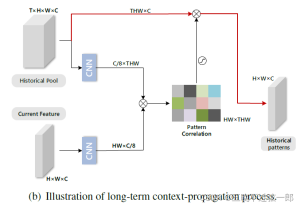
(b) 时间域的混合。历史帧的模式进行相关并传递到当前候选帧用于长时上下文建模。

Comments NOTHING